
")


Free Funnel Audit
Convert more customers today!

SEO
10 mins read

SEO
10 mins read
Python has quietly become one of the most powerful tools in an SEO toolkit, especially when audits, crawling, and data analysis start to feel like an endless loop of spreadsheets and manual checks. When those “quick checks” turn into entire afternoons lost inside exports from your crawler, analytics, and Google Search Console, automation stops being a nice to have and starts feeling like survival.
That is exactly where how Python can be used for SEO in a practical way becomes a very real, very valuable question for anyone managing serious sites.
SEO used to be manageable with a couple of SaaS tools, a crawler, and some patience, but modern sites generate huge amounts of data across thousands of URLs, events, logs, and query reports. Python shines here because it can automate repetitive work, handle large datasets that make spreadsheets choke, and connect multiple tools and APIs into one joined-up workflow. When someone asks how python can be used for SEO, the honest answer is that it becomes the glue between crawling, auditing, and performance analysis instead of juggling a dozen disconnected exports.
For technical SEO specifically, Python allows custom crawling, flexible rules, and tailored checks that no generic crawler can fully match for a particular site architecture. On the analysis side, it lets SEO teams explore trends in Search Console, server logs, and analytics with precision, turning vague patterns into statistically grounded insights that are easy to repeat and update.
Python answers how can Python be used for SEO most clearly when looking at concrete pain points that show up in day-to-day work. Some of the most impactful problems it solves are:
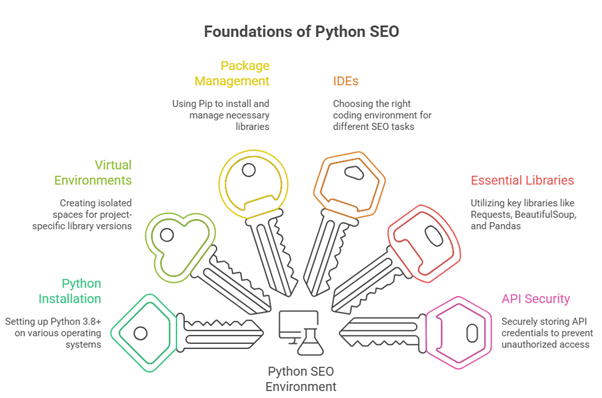
Getting started requires installing Python and setting up a proper working environment. This foundation determines how smoothly everything else functions. Windows, Mac, and Linux users all have straightforward installation paths, though the specifics vary by operating system.
Python 3.x represents the current standard. Version 3.8 or newer provides the stability and features needed for SEO applications. The official Python website offers installers that handle the basic setup process. During installation, adding Python to the system PATH variable saves troubleshooting later. This setting allows running Python from any command line location.
Virtual environments deserve special attention. These isolated spaces let different projects use different library versions without conflicts. Think of them as separate toolboxes for separate jobs. Creating a virtual environment for each major SEO project prevents the “it worked yesterday” frustration that comes from library incompatibilities.
Package managers handle library installation. Pip comes bundled with Python and serves as the primary tool for adding new capabilities. Installing libraries becomes as simple as typing a command. The Python Package Index contains thousands of pre-built libraries covering nearly every SEO need imaginable.
Integrated Development Environments (IDEs) make writing and debugging code more manageable. Jupyter Notebooks offer an interactive approach perfect for data analysis and experimentation. Visual Studio Code provides a lightweight but powerful coding environment. PyCharm delivers enterprise-grade features for larger projects. Each has strengths depending on the specific task.
Essential libraries for SEO work form a core toolkit. Requests handles HTTP operations, fetching web pages, and API data. BeautifulSoup parses HTML, extracting specific elements from web pages. Pandas manipulates tabular data with efficiency that makes Excel jealous. Matplotlib and Seaborn create visualizations that make data insights obvious. These libraries work together, each handling its specialized function.
API credentials require secure storage. Many SEO applications need access to Google Search Console, Google Analytics, or other platforms. Storing API keys directly in code creates security risks. Environment variables or dedicated configuration files keep credentials separate from the main codebase. This separation also makes sharing code safer, since credentials aren’t accidentally included.

Libraries form the backbone of Python’s SEO utility. Requests stand out for their simplicity in making HTTP calls. It supports GET and POST methods, handles sessions, and manages authentication, crucial for API interactions in SEO data gathering.
BeautifulSoup excels at parsing. It navigates DOM trees, selecting elements via CSS selectors or tags. For SEO, this means extracting headings, alt texts, or canonical links effortlessly. Paired with lxml for speed, it handles large documents without lagging.
Scrapy takes crawling to professional levels. It defines spiders that follow links, extract data using XPath, and store outputs in formats like JSON or CSV. Built-in features manage concurrency, retries, and middleware for custom behaviors, making it ideal for site-wide audits.
Selenium bridges the gap for dynamic content. By controlling browsers like Chrome or Firefox, it renders JavaScript, simulates clicks, and captures screenshots. This proves invaluable for auditing interactive elements or testing mobile responsiveness.
Data analysis relies on Pandas. It reads from various sources, merges datasets, and performs operations like grouping or pivoting. SEO applications include analyzing keyword densities or traffic sources.
For visualization, Matplotlib and Seaborn create plots showing ranking fluctuations or backlink distributions. Integrating with Pandas, they turn raw data into actionable visuals.
Advanced users leverage NLTK or spaCy for natural language processing, clustering keywords, or sentiment analysis of content. Machine learning with scikit learn predicts SEO outcomes based on historical data.
API specific libraries, such as GoogleSearch or serpapi, automate search result scraping, monitoring positions without manual queries.
Choosing libraries depends on the task scale. Small projects might stick to core ones, while enterprise-level needs demand robust frameworks. Regular updates ensure compatibility with evolving web standards.
Mastering these libraries unlocks how can python be used for SEO by providing building blocks for tailored solutions. They reduce development time, allowing focus on insights over implementation.
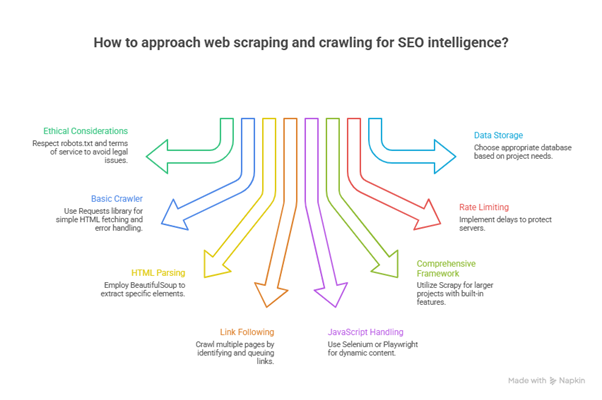
Understanding what competitors are doing, how pages are structured, and what content ranks requires gathering data from actual websites. Web scraping extracts this information systematically, transforming unstructured web pages into analyzable data.
The ethical and legal considerations matter. Respecting robots.txt files isn’t just good practice; it’s respecting website owners’ wishes. Rate limiting prevents overwhelming servers with requests. Some websites explicitly prohibit scraping in their terms of service. Public data generally remains fair game, but checking terms and conditions avoids potential issues.
Building a basic web crawler starts with fetching a page’s HTML. The Requests library sends HTTP requests and receives responses. Error handling ensures the script continues even when pages return 404s or timeout. Setting appropriate user agents identifies the crawler honestly rather than pretending to be a regular browser.
Parsing HTML reveals page structure and content. BeautifulSoup turns messy HTML into navigable objects. Finding specific elements requires understanding HTML structure and CSS selectors. Title tags, meta descriptions, headings, and links all become extractable data points. The parser can identify missing elements just as easily as present ones.
Crawling beyond a single page requires following links. Starting from a homepage, the crawler identifies all internal links, adds them to a queue, and visits each systematically. Tracking visited URLs prevents infinite loops where the crawler revisits the same pages endlessly. Respecting crawl depth limits keeps projects manageable.
Handling JavaScript-rendered content presents additional challenges. Modern websites often load content dynamically after the initial page load. Selenium and Playwright control actual browsers, allowing JavaScript to execute before scraping. This approach consumes more resources but captures the full rendered page.
Scrapy provides a comprehensive framework for larger crawling projects. Rather than building everything from scratch, Scrapy offers built-in functionality for common crawling patterns. Middleware handles robots.txt compliance automatically. Pipelines process scraped data systematically. Concurrent requests speed up large crawls while respecting rate limits.
Rate limiting and polite crawling protect both the crawler and target servers. Adding delays between requests prevents overwhelming servers. Randomizing delay intervals makes crawling patterns less detectable. Monitoring response codes identifies when a site is struggling or blocking requests. Backing off when appropriate maintains access.
Storing crawled data requires structure. Databases handle large volumes better than flat files. SQLite offers a lightweight option for moderate datasets. PostgreSQL or MySQL suits larger projects. NoSQL databases like MongoDB work well for flexible schema requirements. The choice depends on data volume, query patterns, and project complexity.
Crawling and scraping sit at the heart of many Python SEO workflows, and several libraries make that significantly easier. Different libraries suit different needs:
Choosing the right combination depends on whether the main goal is quick validation, full-scale crawling, or complex interaction with JavaScript-heavy sites.
Modern sites often rely heavily on JavaScript, which can limit the effectiveness of basic HTTP requests or simple scrapers. Python addresses this by integrating with browser automation tools that execute JavaScript and render pages more like real users or search engine bots.
With these tools, a script can:
This is especially valuable for SEO checks on e-commerce filters, infinite scroll sections, and complex app-like experiences where indexability depends heavily on the rendered output.
One of the most practical uses of Python in SEO is turning recurring checks into automated alerts that run on a schedule. Instead of manually pulling the same reports every Monday, scripts can check for conditions and only send updates when something meaningful changes.
Common automated checks include:
Alerts can be delivered by email, Slack, or even logged into monitoring dashboards, creating an ongoing early warning system that supports more stable organic performance.
Connecting to Google Search Console through its API is one of the highest value applications for Python in SEO. Instead of being limited by the interface or manual exports, scripts can fetch granular query and page data at scale and on demand.
Using the API, Python can:
This brings Search Console closer to a true analytics data source that can drive strategic decisions, rather than a static interface visited occasionally.
Once Search Console data is available in Python-friendly form, it can be analyzed in ways that are very hard to replicate inside the web UI alone. Scripts can group, compare, and segment data across multiple time windows, URL patterns, and query types.
Practical analyses include:
The end result is faster, more precise prioritization because decisions rest on real patterns across a full dataset rather than a handful of sampled reports.
Server log analysis has always been powerful for technical SEO, but it often feels inaccessible because log files are large and not easy to handle manually. Python is particularly strong here because it is built to process text files and large datasets efficiently.
With Python, log analysis can:
Those insights help align internal linking, sitemaps, and robots directives with real bot behavior instead of guessing how crawlers move through the site.
Backlinks remain among the strongest ranking signals. Analyzing link profiles, finding opportunities, and monitoring link acquisition all benefit from automation.
Backlink data comes from third-party tools. Ahrefs, Majestic, and Moz maintain massive link databases accessible via APIs. Python scripts can retrieve backlink data, process link attributes, and analyze profile health.
Link quality assessment requires examining multiple factors. Domain authority, page authority, spam score, relevance, and link placement all matter. Python can calculate composite quality scores based on weighted factors, identifying high-value links worth pursuing and low-quality links worth disavowing.
Competitor backlink analysis reveals their link-building strategies. Extracting competitor backlinks, identifying common link sources, and finding unique domains linking to competitors guides outreach efforts. Python can compare multiple competitor profiles to find patterns.
Broken link building opportunities emerge when competitors have broken backlinks. Scripts can check competitor backlinks for 404 responses, identify pages that could serve as replacements, and generate outreach lists with contact information.
Link gap analysis compares backlink profiles. Identifying domains linking to multiple competitors but not to the target site creates a qualified prospect list. These domains have already demonstrated a willingness to link to relevant content.
Anchor text distribution analysis prevents over-optimization. Google penalizes manipulative anchor text patterns. Python can categorize anchor text as branded, exact match, partial match, generic, or naked URLs, then calculate distributions and flag unnatural patterns.
Link velocity tracking monitors link acquisition rates. Sudden spikes in new links can trigger scrutiny. Tracking new links over time helps maintain natural growth patterns and identifies successful content or campaigns.
Disavow file management becomes necessary when toxic links accumulate. Python can process large backlink exports, apply quality filters, and generate formatted disavow files. Updating disavow files regularly protects against negative SEO attacks.
Outreach automation assists link-building campaigns. While personalization matters, Python can handle the mechanical aspects: finding contact emails, tracking outreach status, scheduling follow-ups, and recording responses.
Beyond pure technical checks, Python helps with large scale content audits where the goal is to understand coverage, duplication, and topical structure. By combining crawler data with on-page signals and performance metrics, scripts can map how content clusters actually look in practice.
A content-focused workflow can:
This helps teams move from isolated page-level changes to structural topic improvements that support long-term organic growth.
Stakeholders rarely want to see raw data; they want clear stories grounded in evidence. Python helps transform complex datasets into concise, repeatable reports that focus on what changed, why it matters, and where to act next.
Automated reporting workflows can:
This combination keeps decision makers informed while allowing the SEO team to spend more time thinking and less time reshaping exports.
The idea of learning a programming language can feel intimidating for anyone with a content or marketing background, but Python is notably beginner-friendly. Many SEO oriented learning resources focus on small, repeatable scripts that solve common tasks rather than abstract computer science concepts.
A pragmatic learning path usually includes:
Over time, the comfort level grows from running scripts from others to adapting them, and eventually to designing new workflows tailored to actual site challenges.
Teams already invested in multiple SEO platforms do not need to abandon them when adopting Python. Instead, Python often lives alongside these tools as an enhancement layer that fills gaps in customization, scale, or historical analysis.
Effective integration usually means:
This hybrid approach respects existing workflows while gradually increasing the level of automation and analytical depth available to the team.
In the end, Python is not about showing off technical skills; it is about regaining time and clarity in an environment where manual work does not scale. For anyone still wondering how can python be used for SEO, the most honest answer is that it becomes a quiet partner handling the heavy lifting in audits, crawling, and data analysis so humans can focus on strategy, creativity, and meaningful decisions.
When the same problems keep resurfacing across exports, crawls, and reports, that is usually the signal that Python would help, whether it is automating technical checks, pulling richer Search Console data, or making sense of complex crawl and log behavior. By starting small, focusing on real bottlenecks, and building from there, Python gradually moves from a curiosity to an essential part of serious SEO operations.
Lead generation for architects means helping the right people discover your firm. These people already have a real need for architectural services. The goal is to build trust early so the first conversation feels comfortable.
Yes, online lead generation works when it supports how clients research. Most people look online before they contact an architect. Helpful content and a clear website guide them during that early stage.
Lead generation rarely works overnight in architecture. Clients often take time to plan, budget, and compare options. With consistency, better inquiries usually appear within a few months.
Small firms benefit from simple and focused efforts. Clear messaging, helpful content, and referrals often work well together. These approaches build visibility without requiring large marketing budgets.
Start using our A/B test platform now and unlock the hidden potential of your website traffic. Your success begins with giving users the personalized experiences they want.
Start Your Free Trial
Empowering businesses to optimize their conversion funnels with AI-driven insights and automation. Turn traffic into sales with our advanced attribution platform.
Trusted by Customers


©CausalFunnel Inc. All rights reserved.